In this post I will be covering details of deployment of PostgreSQL High Availability on Bare Metal VM's. This article is part of series of Harbor High Availability
-
Harbor High Availability deployment on Kubernetes
Post 01 - Harbor High Availability deployment on Kubernetes\
-
Kubernetes Dynamic Provisioning : Persistent Volume on demand (Using helm charts)
Kubernetes Dynamic Provisioning - Persistent Volume on demand (Using helm charts) \
-
High available Redis (Using helm charts)
-
High available PostgreSQL database (Using helm charts) (this post)
-
Harbor High Availability deployment in action on Kubernetes using helm chart.
PostgreSQL is an open source object-relational database known for its reliability and data integrity.
Prerequisite
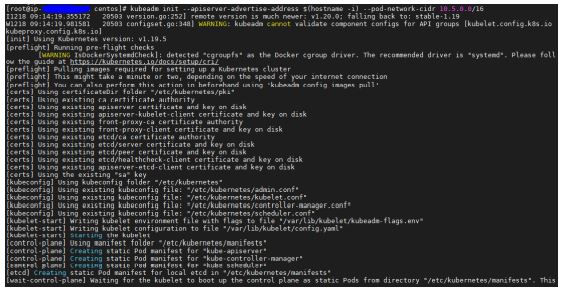
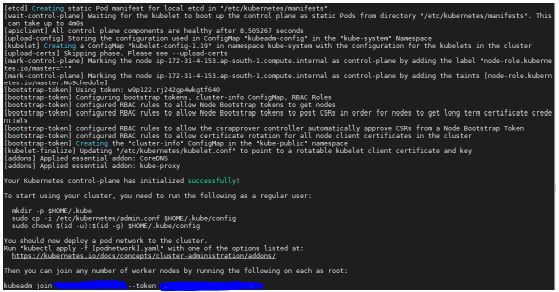
- Kubernetes cluster is up and running. To know how to achieve this read my previous post bootstrap kubernetes using kubeadm.
- NameSpace with name harbor-private-registry is already existing.
If its not created run:
$ kubectl create ns harbor-private-registry
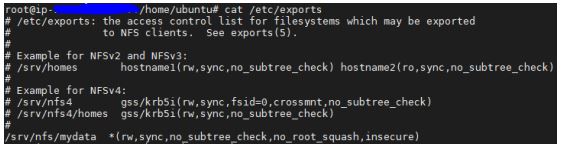
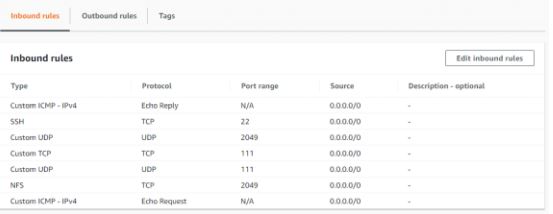
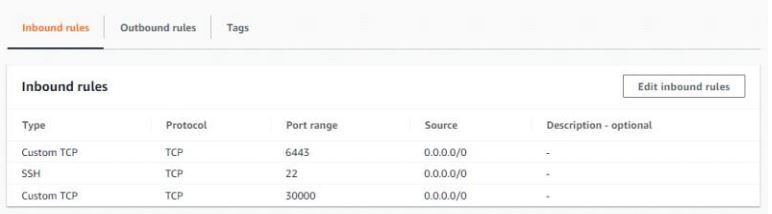
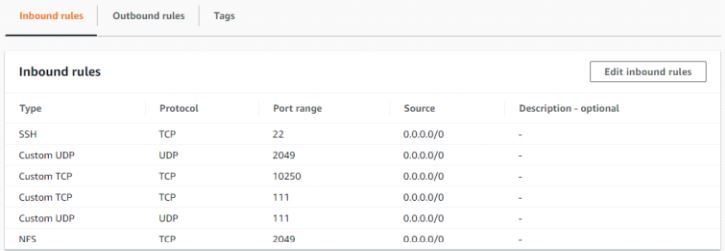
- Dynamic Volume Provisioning NFS is working and able to create pv on demand.
Using helm chart for PostgreSQL High Availability cluster
We will be using bitnami helm chart for deploying High Availabilty PostgreSQL cluster - PostgreSQL helm
We need to modify values.yaml file or override below values using --set flag while installing helm:
--set pgpool.replicaCount=2
--set postgresql.replicaCount=3
--set postgresql.existingSecret=postgresql-harbor-secret : Name of secret created to store postgreSQL and repmgr password
--set pgpool.adminPassword=MTk5MCRwb3N0Z3Jlc3Fs
--set pgpoolImage.tag=4.2.2-debian-10-r72
--set postgresqlImage.tag=13.2.0-debian-10-r77
--set global.storageClass=nfs-client : Value (nfs-client) is name to storageClass created with NFS Dynamic Provisioner.
--set service.type=ClusterIP
Note : Creating below Secret is important else you wont be able to reattach existing pv on next uninstall and reinstall of postgreSQL helm chart due to any reason.
Important Steps to create Secret (don't miss this)
Create secret for configurable parameter of bitnami postgreSQL HA Helm chart values.yaml postgresql.existingSecret
Create secret using below command and then install postgreSQL using helm chart:
You will get below output on successfull installation of helm chart:
NAME: postgresql-harbor-private-registry
LAST DEPLOYED: Fri May 15 12:19:43 2021
NAMESPACE: harbor-private-registry
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES: \
Please be patient while the chart is being deployed
PostgreSQL can be accessed through Pgpool via port 5432 on the following DNS name from within your cluster:
postgresql-harbor-private-registry-pgpool.harbor.svc.cluster.local
Pgpool acts as a load balancer for PostgreSQL and forward read/write connections to the primary node while read-only connections are forwarded to standby nodes.
To get the password for "postgres" run:
export POSTGRES_PASSWORD=$(kubectl get secret --namespace harbor-private-registry postgresql-harbor-private-registry-secret -o jsonpath="{.data.postgresql-password}" | base64 --decode)
To get the password for "repmgr" run:
--command -- psql -h postgresql-harbor-private-registry-pgpool -p 5432 -U postgres -d postgres
To connect to your database from outside the cluster execute the following commands:
*psql -h 127.0.0.1 -p 5432 -U postgres -d postgres *
Once the pods are up and running exec into postgreSQL stateful set pod and run *psql -h 127.0.0.1 -p 5432 -U postgres -d postgres *
Enter the password you get from *kubectl get secret --namespace harbor-private-registry postgresql-harbor-private-registry-secret -o jsonpath="{.data.postgresql-password}" | base64 --decode *
Create following database for harbor. Tables will be created automatically when Harbor HA starts
CREATE DATABASE notary_server;
CREATE DATABASE notary_signer;
CREATE DATABASE harbor_core;
postgres-# \l (this will list all the database)
Architecture of helm chart deployed
Images used while deploying this helm chart:
1) bitnami/postgresql-repmgr :
PostgreSQL is an open source object-relational database known for its reliability and data integrity. This solution includes repmgr, an open-source tool for managing replication and failover on PostgreSQL clusters.
2) bitnami/pgpool :
Pgpool-II is a PostgreSQL proxy. It stands between PostgreSQL servers and their clients providing connection pooling, load balancing, automated failover, and replication.
After you deploy PostgreSQL HA using helm chart it will deploy two Pod's of pgpool and three pods of postgresql-repmgr
pgpool is a deployment and postgresql-repmgr is a stateful set.
This will create one master and two slave cluster where Pgpool will be responsible for promoting slave to master incase master goes down.
Master (pod/postgresql-harbor-postgresql-0) will be single point for write operation where as master and two slaves (pod/postgresql-harbor-postgresql-1 and pod/postgresql-harbor-postgresql-2) will be three point for read operation.
pod/postgresql-harbor-pgpool-23243g54f8-afdsc
pod/postgresql-harbor-pgpool-11834437d4-ojgfd
pod/postgresql-harbor-postgresql-0
pod/postgresql-harbor-postgresql-1
pod/postgresql-harbor-postgresql-2
Two Cluster IP service will be created and one headless service.
PGPool pod's can be reached through pgpool cluster IP service and postgreSQL pods communicate to postgresql service.
For integration with harbor HA pass Pgpool Cluster IP as PG internally communicates to postgreSQL master and slave using headless service.
In the next post I will be deploying Harbor Helm and details of Integration with Redis and PostgreSQL cluster -
Kubernetes Dynamic Provisioning - Persistent Volume on demand (Using helm charts)